
今天,我们正式发布工业级语音合成系统 GLM-TTS,并在 Hugging Face 和 ModelScope 上开放模型权重。
基于在数据筛选、基础模型结构、精品音色监督微调(SFT)范式和强化学习(RL)范式等多方面创新,GLM-TTS 仅在 10w 小时数据上训练,便具备了“3 秒”音色复刻和超强文本理解能力,字错误率和情感表达在多个开源测试集上实现开源 SOTA。
即刻起,用户可在 Z.ai(audio.z.ai)、智谱清言 APP/网页版(chatglm.cn)上体验 GLM‑TTS ;在开放平台 BigModel 上调用模型 API。欢迎广大开发者、企业、用户广泛测试与集成。
在这篇技术博客中,我们主要介绍 GLM-TTS 的技术概况。
整体系统
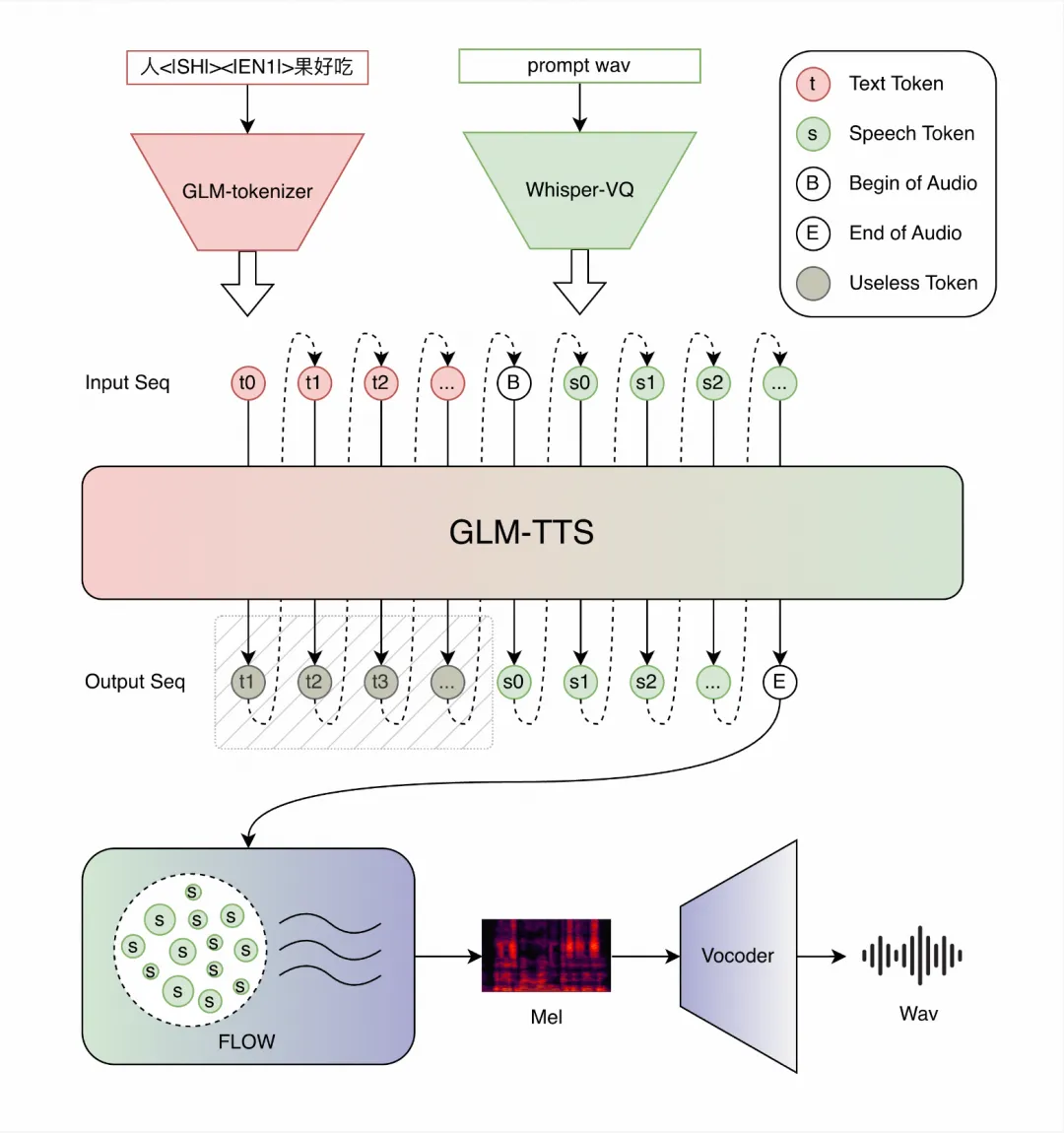
GLM-TTS 是一套基于两阶段生成范式的高质量语音合成系统,由 Text-to-token Auto-regression 与 Token-to-wav Diffusion 两大核心模块构成。
1. 核心架构与工作流
GLM-TTS 的生成流程主要分为两个阶段:
- 第一阶段:语义建模(Text-to-token)
- 输入:Prompt 文本、Prompt 音频 Token、待生成文本。
- 处理:基于自回归(Auto-regression)生成对应的 Whisper-VQ 语义 Token 序列,确保内容的准确性与连贯性。
- 第二阶段:声学建模与波形重建 (Token-to-wav)
- 输入:语义 Token、音色 Prompt。
- 处理:进入 Conditional Flow-matching 模型预测梅尔频谱图。
- 输出:通过自研 2D-Vocos 声码器,将梅尔频谱图转换为高保真、高质量的语音波形。
2. 关键技术突破
GLM-TTS 在模型训练、发音控制及表现力优化等方面实现了多重创新:
- Speech Tokenizer:基于 GLM-4-Voice Speech Tokenizer 进行优化,引入基频约束并提升 Token Rate。此举显著增强了合成语音的发音准确性、自然度及表现力。
- 强化学习:基于 GRPO 算法框架,融合了 CER、Similarity、Emotion 及 Laughter(笑声副语言)的多维度正则化奖励机制。配合动态采样与梯度裁剪策略,显著提升了语音的拟人化情感表达能力。
- 精品音色定制(LoRA): 采用优化的 LoRA 范式,仅需微调 15% 以上参数及少量 epoch,即可达到与全参数微调相当的效果。这大幅降低了单一说话人精品音色模型的开发成本与落地门槛。
- 精细化发音控制(Phoneme-in):针对教育评测等高精度场景,构建了可动态扩展的多音字与生僻字词表。通过 “Hybrid Phoneme + Text” 的混合输入形式,有效解决了多音字混淆和生僻字发音不准的难题。
- 2D-Vocos 声码器:创新引入 2D 卷积与类 DiT 残差连接,实现了对频率子带的高效建模与频谱特征的精准还原。配合高质量歌声数据混合训练,有效拓宽了音域覆盖范围,显著增强了复杂声线下的合成音质与模型适应性。
3. 技术细节与演进
接下来,我们将从以下六个维度详细拆解 GLM-TTS 的技术实现:
数据处理 Pipeline、Speech Tokenizer、强化学习、精品音色定制(LoRA)、精细化发音控制、2D-Vocos 声码器。
1)数据处理 pipeline

我们构建了完善的数据处理 pipeline,整体流程如下:
- 语音标准化与粗切:统一异构音频为 WAV 格式,经 VAD 切分有效片段并拼接为 10 分钟左右长音频,供后续处理。
- 背景音分离与降噪:通过 Mel-Band Roformer 模型分离背景音保留语音,再经自研降噪模型处理得到纯净语音。
- 说话人分离与拼接:基于 pyannote 模型完成多说话人分离,对单人片段进行幅度归一化拼接,拼接长度达标(>40s 即停止)。
- WER 筛选:中文用开源 ASR 模型 paraformer/sensevoice、英文用开源 ASR 模型 whisper/reverb 模型识别文本并计算 WER double check,保留 WER<5% 的高质量数据。
- 标点优化:通过文本-语音强制对齐获取字发音时长,计算发音阈值(均值+2.6*方差),依据字间间隔与阈值的关系优化标点(间隔超阈值则保留/添加,否则去除/不添加)。
- 特征提取:基于筛选后的单人纯净音频提取特征,支撑后续模型训练。
- 整体工程优化:采用 gRPC 框架与 server-worker 架构,各子模块工程加速,依托分布式集群实现大规模数据处理,高效利用多卡显存与 batch 处理能力。
2)Speech tokenizer 更新
GLM-TTS 基于 GLM-4-Voice 的 Whisper-VQ speech tokenizer,进行以下优化,提升发音准确性、自然度和表现力:
- 提升 token 码率(12.5Hz→25Hz)并扩大词表规模(16k→32k),优化高速语速下的发音卡顿问题,增强笑声、呼吸等副语言的合成自然度;
- 新增 Pitch Estimator(PE)音调估计模块,优化音调建模精度,提升克隆 TTS 对参考音频(prompt)的韵律遵从度;
- 取消原有 causal 限制,移除 block attention 结构并将因果卷积(causal conv)替换为标准卷积,打破时序束缚以提高 ASR 与 PE 模块准确率;
- 扩充训练数据维度,新增海量方言语料强化方言理解力,补充高质量歌声数据丰富模型发声学习样本,提升多元场景适配性;
实验结果:
- ASR 指标:方言 ASR 显著优于 GLM-4-Voice_tokenizer,英文 ASR 小幅度优化。

注:值表示 WER 或 CER,越低越好。*表示胶辽地区重口音普通话。
- TTS seed_tts_eval 中文指标

3)多奖励融合强化学习
当前强化学习在语音合成领域尚未得到广泛应用,核心瓶颈在于奖励机制设计难度大、训练过程易出现梯度消失或模型负优化等问题。GLM-TTS 通过引入 GRPO 强化学习范式和一系列精细设计,显著提升了预训练模型和 SFT 模型的基础能力(含发音准确性、音色相似度等核心指标)和拟人化程度(涵盖情感表达精度、副语言自然度等高阶需求)。

核心方案及创新亮点如下,整体采用 GRPO 算法框架,通过三大创新性设计实现性能跃升:
- 其一,创新设计多维度正则化奖励机制,融合 CER(字符错误率)、Sim(相似度)、Emotion(情感)、Laughter(副语言笑声)四大核心奖励,通过“单奖励独立正则化→权重加权融合→总体正则化”的分层处理逻辑,解决不同奖励分布差异过大的痛点问题;
- 其二,采用动态采样策略,针对 batch 内奖励加权趋同可能导致的梯度消失问题,自动触发重采样(最多三次),同时通过限制采样次数避免过差样本引入的模型负优化,兼顾训练稳定性与效率;
- 其三,动态梯度裁剪参数方案,将 clip_high 与 clip_low 设为随训练步数自适应调整的动态值:训练初期收紧限制,规避模型快速陷入 reward hacking 捷径;后期逐步放开,赋予模型更大探索空间;同时通过合理设定参数范围,保障 clip 的 token 数量平稳,避免裁剪失效或过度限制,且通过 clip_high 高于 clip_low 的设计,有效鼓励低概率 token 生成,大幅提升语音拟人化表现力。
强化学习采用了训练数据与合成数据相结合的数据构造模式,实现了几乎零成本的数据生成。结合训练算法的优化,有效避免了奖励欺骗(reward hacking),从而保证了模型性能的真实性和泛化能力,在未见过的测试集上同样取得了理想效果。
实验结果:
在 seed-tts-eval 中文测试集中,我们的预训练阶段模型(GLM-TTS、GLM-TTS_RL)以 “提升零样本音色克隆发音准确度(CER)+ 音色相似度(Sim)” 为核心优化目标。实验表现如下:
- CER(字符错误率)表现:GLM-TTS 的 CER 达 1.03%,处于开源模型第一梯队;GLM-TTS_RL 进一步将 CER 优化至开源“SOTA”-> 0.89%,这一结果不仅优于 CosyVoice2(1.38%)、IndexTTS2(1.03%)、VoxCPM(0.93%)等主流开源模型,并接近闭源模型的顶尖水平。
- Sim(音色相似度)表现:GLM-TTS 的 Sim 相似度为 76.1,GLM-TTS_RL 提升至 76.4,在开源模型中处于中上游水平;结合低 CER 表现,验证了预训练阶段对 “发音精准 + 音色相似” 的双维度优化效果。

在 SFT 阶段,我们聚焦文本理解能力和情感表达。在 CV3-eval-emotion 测试集的 text_related 中文数据集(文本自带情感倾向)中,GLM-TTS SFT 精品音色模型聚焦情感表达,对比市面商用 TTS 大模型展现出显著优势:
- 情感表达的领先性:GLM-TTS - 精品音色_RL 在 Happy(0.72)、Sad(0.52)、Angry(0.28)三类情感维度均取得 “测试集最佳表现”,平均情感得分(avg_emo)达 0.51;而阿里 Qwen3-TTS、百度超拟人 TTS、豆包 TTS-2.0 等商用模型,仅在 Happy 维度有部分表现,但在 Sad、Angry 等负向情感上几乎无有效输出(得分多为 0)。这一差异验证了我们的模型具备良好的文本情感理解能力,可根据文本内容自动适配对应情感风格。
- 字错误率的优势:在情感表现领先的同时,GLM-TTS CER 仍显著低于其他商用模型:GLM-TTS - 精品音色的 CER 仅为 1.33,GLM-TTS - 精品音色_RL 的 CER 为 1.68,均优于市面其他商用模型,实现了 “情感表达 + 发音准确度” 的双重领先。

4)精品音色定制(LoRA)
在语音大模型的 SFT 流程中,全参微调受数据分布与质量不均影响,难以形成稳定通用范式,人力、工程及评测成本高昂,且无法满足小批量个性化精品音色定制的落地需求。
因此,我们引入并优化了 LoRA 微调训练范式。
- 高效与效果对标:仅需微调核心骨干网络中约 15% 左右的参数,配合约 100 个 epoch 的训练,即可实现与全参数微调相媲美的音色还原度与自然度。
- 低成本定制: 仅需约 1 小时的单一说话人高质量音频数据,即可完成定制,有效避免了全参微调所需的大规模数据配比筛选和复杂的评测流程,大幅降低了开发成本和落地门槛。
- 音色稳定性提升:实验结果表明,通过将微调参数比例精准控制在特定范围(如 15% 以上),音色泛化能力与跨场景稳定性得到显著增强,确保了定制音色的工业级可靠性。
5)精细化发音控制(Phoneme-in)
在教育评测、专业配音及有声读物等对发音准确性要求极高的严肃应用场景中,多音字(如“行”xíng/háng) 和生僻字的自动发音歧义是传统 TTS 模型的关键挑战。模型通常依赖内部语言模型进行推断,但缺乏外部强制干预机制,易导致发音错误和应用体验受损。
我们提出了 Phoneme-in 可控读音增强能力,通过引入音素级(Phoneme-level)输入,实现对模型发音的精准、定向控制:
a.关键组成部分:
- 动态可控词典:专门针对易产生发音歧义的词条(主要是多音字和生僻字)及其所需的目标发音。它是实现定向音素替换的基础。
- GLM-TTS 模型:最终的语音合成模型,能够接受 “Hybrid Phoneme + Text”的混合输入。
b.训练阶段: - 增强泛化性训练:对普通文本中的部分字词进行随机地进行 G2P。增强模型对音素输入序列的泛化适配性。
- 关键词条保留:易有歧义的词保留原文进行训练。确保模型保留对纯文本输入的正常处理能力。
c.推理阶段: - 获取完整音素序列:首先,通过 G2P 模块对整个待合成文本获取完整的音素序列。得到未经用户干预的初始音素序列。
- 定向音素替换:基于动态可控词典,系统识别文本中特定的多音字或生僻字,并将其与上述生成音素序列中的对应部分进行替换。实现对歧义发音的精准、定向控制。
- 混合输入推理:将替换后的音素与文本一起,以 “Hybrid Phoneme + Text” 的混合输入形式传入 GLM-TTS 模型。保留文本原有韵律,同时输出字词发音精准可控的语音。
6)2D-Vocos 声码器

针对声码器核心效果提升,重点开展两方面优化,输入为 50Hz Mel 频谱、输出为 32k 高采样率 WAV:
- 其一,模型结构升级,在 Vocos 基础上进行关键改进,将原有 1D 卷积替换为 2D 卷积,实现对频率子带的更高效建模,提升频谱特征解析精度;同时引入类 DiT 残差连接机制,可快速将输入频谱信息引入骨干 ConvNeXt 层,更充分地利用频谱条件,强化输入与输出的关联一致性。
- 其二,训练数据增强,在高质量语音训练数据的基础上,额外融合大量高质量歌声数据,此类数据具备音域更广、发声方式更丰富的特性,不仅能有效提升最终32k高采样率WAV输出的音质,还能显著增强声码器对不同声音类型的适应性与训练稳定性。
开始使用 GLM‑TTS
1.在线体验
通过以下入口快速体验 GLM‑TTS 的合成效果:
- audio.z.ai:上传文本或短语音 Prompt,生成专属声音;
- 智谱清言 APP / 网页版:在对话中体验多风格朗读与音色克隆。
2.开放平台与 API
如希望直接接入线上业务,可以通过开放平台调用 GLM‑TTS 能力:
- 开放平台入口:
https://docs.bigmodel.cn/cn/guide/models/sound-and-video/glm-tts
API 接口文档: https://docs.bigmodel.cn/api-reference/模型-api/文本转语音
https://docs.bigmodel.cn/api-reference/模型-api/音色复刻
平台支持多种计费和 QPS 配置,覆盖从 Demo 试用到生产级大规模调用。
https://docs.bigmodel.cn/cn/guide/models/sound-and-video/glm-tts
https://docs.bigmodel.cn/api-reference/模型-api/文本转语音
https://docs.bigmodel.cn/api-reference/模型-api/音色复刻3.模型开源
我们将在主流开源社区开放 GLM‑TTS 相关资源(模型权重、推理脚本、示例项目等):
- GitHub:https://github.com/zai-org/GLM-TTS
- Hugging Face:https://huggingface.co/zai-org/GLM-TTS
- 魔搭社区:https://modelscope.cn/models/ZhipuAI/GLM-TTS
开发者可以基于主流推理框架,在 GPU 环境中快速部署 GLM‑TTS,并按需做二次开发。







 琼ICP备2025054846号-2
琼ICP备2025054846号-2