










MiniMax Speech 02基于超强技术与足够泛化的模型能力,Speech-02为用户带来超拟人、个性化、多样性的语音服务。Speech-02通过“文生音”功能给定自然语言文本描述生成符合描述的音色;通过“声音参考”功能,对任意给定语音实现灵活控制,进行感情、语速、音高、语种等无缝切换;同时支持粤语、葡萄牙语、法语等32个语种,甚至在同一段语音里也可以实现多个语种间的自如切换。

在国际权威的Artificial Analysis 上,MiniMax Speech 02也通过全球用户测评,位列全球第一。
权威双榜,全球第一
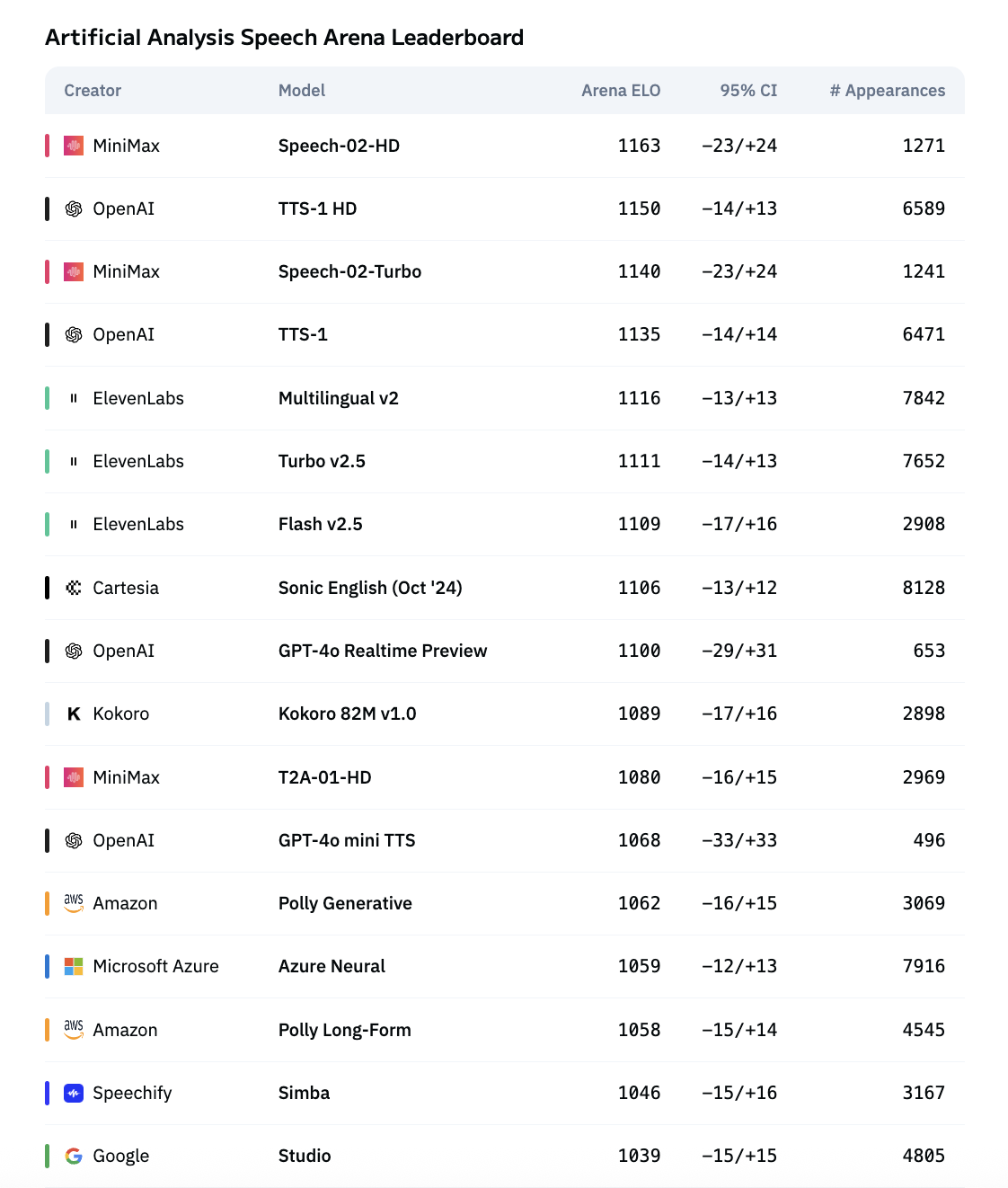
在两项全球权威语音基准测评榜单:Artificial Analysis Speech Arena 和 Hugging Face TTS Arena 中, MiniMax Speech(在榜中对应为Speech-02-HD)超越了OpenAI、ElevenLabs 等全球性能优异的模型,双双位列第一。
在专业指标测评外,Arena 榜单的 ELO 评分,是根据用户在随机听取并比较不同模型的语音样本时,选出更优的结果来得出的;榜单结果证明,从用户体验上, MiniMax Speech 02 的听感更加优异。

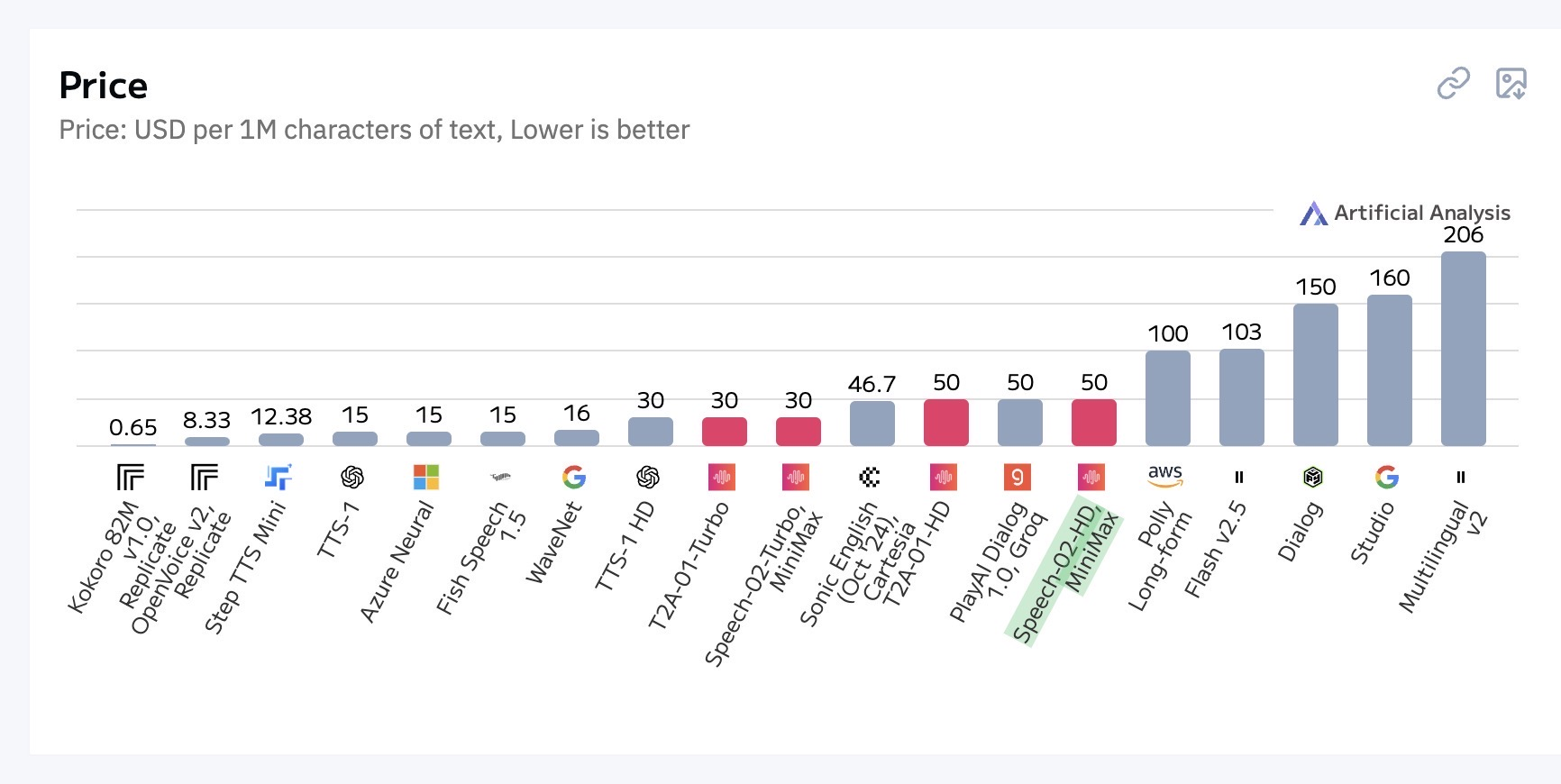
在提供更优异听感同时,MiniMax Speech 02 做到了价格更低,分别是 ElevenLabs Flash V2.5 与 Mutilingual V2 的一半与四分之一。
模型架构带来的灵活性
「会学习的音色提取器」本质上是一个人声编码器( speaker encoder),它能够将任意长度的音频片段转化为固定尺寸的条件向量,从而实现高质量、灵活的声音表达。

Zero-shot带来超拟人的音色:只需要一段参考音频,不需与之对应的文本;这种Zero-shot的方式中,编码器仅从参考音频中提取音色特征,因此更能捕捉声音的本质——音色、音调和风格等特征,从而带来对韵律更灵活广泛的解码空间,最终的输出效果媲美真人,且比真人更加稳定。
32种语言高质量合成:在处理参考音频过程中,Speaker encoder处理音色特征时与语义内容解耦;由于 Speaker encoder 是 learnable的,它可以在训练数据集所涵盖的所有语言上进行训练。这也是MiniMax Speech从本质上支持32种多语种,且跨语言效果更优异的原因。
可扩展功能与个性化表达: 由于speaker encoder 所实现的条件向量本身也可解耦,赋予MiniMax Speech下游应用扩展的灵活性,我们实现了任意音色灵活情感表达、基于语音描述生成音色、以及基于特定说话人的克隆增强等功能。这些功能使得MiniMax Speech进一步丰富个性化语音空间。
 琼ICP备2025054846号-2
琼ICP备2025054846号-2